create table clientes
(
id int auto_increment primary key,
cif varchar(20) not null,
nombre varchar(200) not null,
nusers int,
ndocuments int,
docusfinished int,
daystofinish int,
api int,
web int,
... otros campos de interés
)Machine Learning con Groovy
- abril, 27 2024
- Jorge Aguilera
- 08:00
Recientemente he participado en lo que podría ser mi primer proyecto con Machine Learning. En concreto el proyecto consiste en catalogar a unos mil clientes en función de una serie de atributos (unos 15) de tal forma que nos ayude a comprender mejor sus necesidades.
El proyecto no requiere (ahora mismo) de un análisis en real-time sino que vamos a iterando y mejorando las características y sacando conclusiones en cada una.
En esta fase del proyecto no hace falta acudir a diferentes fuentes de datos sino que vamos a trabajar con los datos "consolidados" que ya disponemos. Es decir, vamos a calcular para cada cliente:
-
el número de usuarios que utilizan nuestra aplicación (hay clientes con un sólo usuario y otros con un pool de ellos)
-
el número de documentos que empiezan y el número de documentos que completan
-
el tiempo, en días, que emplean para completarlos
-
si usan el interface web o el api
-
etc
Preparación de datos
Así pues la primera tarea es revisar las fuentes de datos y "su calidad". En nuestro proyecto hemos revisado las diferentes tablas de las qe disponemos y preparado una base de datos donde consolidarlas.
Esto ha sido por la comodidad de usar algo que es compartido entre los diferentes miembros del proyecto y su rapidez. En otros proyectos o artículos verás que usan ficheros CSV o sistemas más o menos complejos según sus necesidades. En realidad, al menos para nuestro caso, esto es irrelevante, lo único que queremos es tener un sitio que sea cómodo de donde leer los datos
Así pues se han creado una serie de "select count, group, sum, diff" que nos permitan obtener los diferentes contadores por clientes e insertarlos en una tabla
Este proceso ha sido incremental, es decir, hemos empezado con unos pocos campos e ido añadiendo según analizábamos el modelo y las herramientas.
Datos
La idea principal es disponer de una serie de registros donde cada uno representa los atributos de un cliente, lo cual coincide con la idea de un query SQL y que Groovy nos permite leer al vuelo.
Definimos un mapa metadata donde podremos asociar los nombres de los campos MySQL con un nombre más legible
y prepararemos con los datos de tabla un data :
var metadata = [
'Users' : 'nusers',
'Documents': 'ndocuments',
'Finished' : 'docusfinished',
'Days' : 'daystofinish',
'API' : 'template',
'Web' : 'web',
...
]
var rows = mlDB.rows("select * from ml.clientes order by nombre")
var fields = metadata.values()
var data = rows.collect { row ->
fields.collect { row[it] ?: 0.0 } as double[]
} as double[][]Así en data tenemos una matriz de NxM con los datos de los clientes
Groovy y Apache Ignite
A diferencia de la mayoría de los post que encontrarás por ahí nosotros no hemos usado Python, sino Groovy. No voy a detallar las razones, pero básicamente es porque puedo.
Por la parte de Machine Learning, existen diferentes frameworks con capacidades para ello, pero Ignite se integra muy bien con Groovy y ha sido muy fácil usarlo. En mi equipo, un portátil normal, y con un script de Groovy de unas cuantas líneas, el proceso de generar el cluster de clientes tarda apenas unos segundos sin necesidad de crear ninguna infraestructura especial.
@Grab("org.apache.ignite:ignite-core:2.15.0")
@Grab("org.apache.ignite:ignite-ml:2.15.0")
@Grab("org.apache.ignite:ignite-spring:2.15.0")
import org.apache.ignite.cache.affinity.rendezvous.RendezvousAffinityFunction
import org.apache.ignite.cache.query.ScanQuery
import org.apache.ignite.configuration.CacheConfiguration
import org.apache.ignite.configuration.IgniteConfiguration
import org.apache.ignite.ml.clustering.kmeans.KMeansTrainer
import org.apache.ignite.ml.dataset.feature.extractor.impl.DoubleArrayVectorizer
import org.apache.ignite.spi.discovery.tcp.TcpDiscoverySpi
import org.apache.ignite.spi.discovery.tcp.ipfinder.multicast.TcpDiscoveryMulticastIpFinder
import static org.apache.ignite.Ignition.start
var cfg = new IgniteConfiguration(
peerClassLoadingEnabled: true,
discoverySpi: new TcpDiscoverySpi(
ipFinder: new TcpDiscoveryMulticastIpFinder(
addresses: ['127.0.0.1:47500..47509']
)
)
)
start(cfg).withCloseable { ignite ->
// alimentar a Ignite
}Aunque el script es más complejo (y lo iré desgranado a continuación) este código básicamente lo que hace es levantar en nuestra máquina una instancia de Ignite de un sólo nodo.
A continuación creamos una cache
var dataCache = ignite.createCache(new CacheConfiguration<Integer, double[]>(
name: "TEST_${UUID.randomUUID()}",
affinity: new RendezvousAffinityFunction(false, 10)))y le alimentamos con los datos de data. Insertaremos los datos de todos nuestros clientes porque no son millones
de registros, sólo unos miles
data.indices.each { int i ->
dataCache.put(i, data[i]) // estamos insertando en la fila "i" un array de doubles
}Entrenando el modelo
A continuación vamos a decirle a Ignite que entrene al modelo con los datos proporcionados:
var vectorizer = new DoubleArrayVectorizer()
var trainer = new KMeansTrainer()
.withAmountOfClusters(CLUSTERS)
.withMaxIterations(100)
.withEpsilon(1.0E-14)
var mdl = trainer.fit(ignite, dataCache, vectorizer)
var centroids = mdl.centers*.all()CLUSTERS es el número de agrupaciones en las que queremos categorizar a nuestros clientes. Para nuestro proyecto hemos empezado con 3, pero ahora estamos probando con 10 para conseguir mayor "granuralidad"
Esta es la parte central y más difícil de entender de este método de ML. Lo que hace el algoritmo de KMeans es tomar CLUSTERS puntos aleatorios y de forma repetitiva (nosotros forzamos a 100 veces) va analizando cada fila de datos y viendo la distancia "matemática" que hay con esos puntos. En cada paso irá colocando a esa fila en un grupo u otro, de tal forma que al final del bucle unos registros estarán en un grupo y otros en otro.
El elemento aleatorio de dónde ubicar los puntos (centroides) iniciales hace que si ejecutas el proceso diferentes veces obtengas diferentes resultados. Por eso estoy forzando al trainer a que la distancia entre los elementos sea muy muy reducida y a que se ejecute hasta 100 veces obteniendo así las mismas (o parecidas) agrupaciones todas las veces que se ejecuta el script.
Una vez ejecutado el trainer lo que obtenemos es un array de los puntos "centrales" de cada agrupación
Alimentando al modelo
Por último lo que vamos a hacer es, usando el modelo entrenado, "predecir" uno a uno cada cliente e ir acumulándolos
en un mapa en memoria clusters , además vamos a guardar las observaciones de cada uno en otro mapa
observationMap para tener un mayor detalle. Este segundo map lo usamos para generar un report más específico
pero por no complicar este post no voy a entrar en detalles
// Predict all data
var clusters = [:].withDefault { [] } as Map<Integer, ArrayList>
var observationsMap = [:].withDefault { [:].withDefault { [] as Set } }
dataCache.query(new ScanQuery<>()).withCloseable { observations ->
observations.each { observation ->
def (k, v) = observation.with { [getKey(), getValue()] }
def vector = vectorizer.extractFeatures(k, v)
int prediction = mdl.predict(vector)
clusters[prediction] += companies[k]
v.eachWithIndex { val, idx ->
observationsMap[prediction][features[idx]] += val
}
}
}Generando conclusiones
Una vez hemos realizado todas las predicciones tendremos en las variables clusters y
observationsMap suficiente información de cada grupo así como por cada cliente y podremos sacar conclusiones e
incluso podremos generar gráficas
int clusterIdx = 1
clusters.sort { e -> e.value.size() }.each { k, v ->
println "\nCluster ${clusterIdx}: ${v.sort().join(', ')}"
def chart = new RadarChartBuilder().width(1024).height(768).title("Cluster ${clusterIdx}: ${v.size()} Empresas").build()
chart.radiiLabels = features as String[]
chart.styler.with {
legendVisible = true
seriesColors = [
new Color(255, 51, 151, 50)
] as Color[]
}
chart.addSeries("Serie".toString(), normalized)
def bufferedImage = BitmapEncoder.getBufferedImage(chart)
var outputfile = new File("cluster_${clusterIdx}.png")
ImageIO.write(bufferedImage, "png", outputfile)
clusterIdx++
}Ejemplo
Tras ejecutar el script obtenemos gráficas de cada cluster (podríamos tenerlos todos en una pero interpretar tanta info resulta un poco confuso así que hemos preferido crear una imagen por cluster) como por ejemplo:
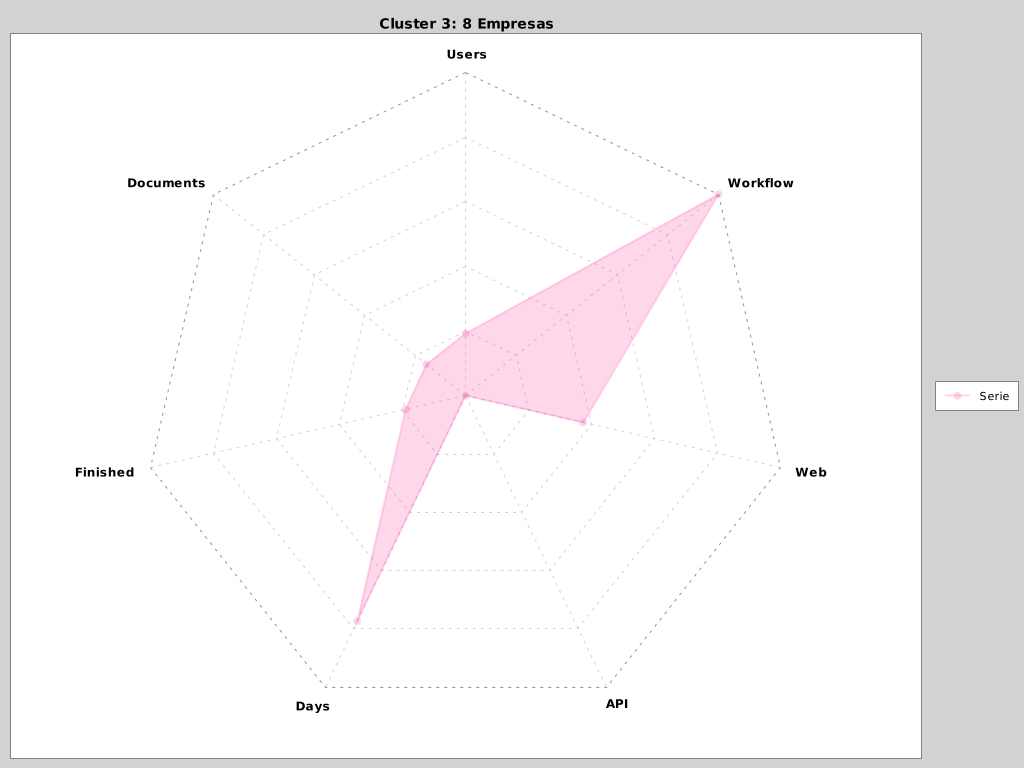
Figure 1. Ejemplo de cluster
Estas agrupaciones nos ayudan a determinar qué empresas en concreto están tardando muchos días en completar el proceso de documentos y que además tienen una baja tasa de terminados lo que indica que están teniendo problemas de usabilidad con la aplicación
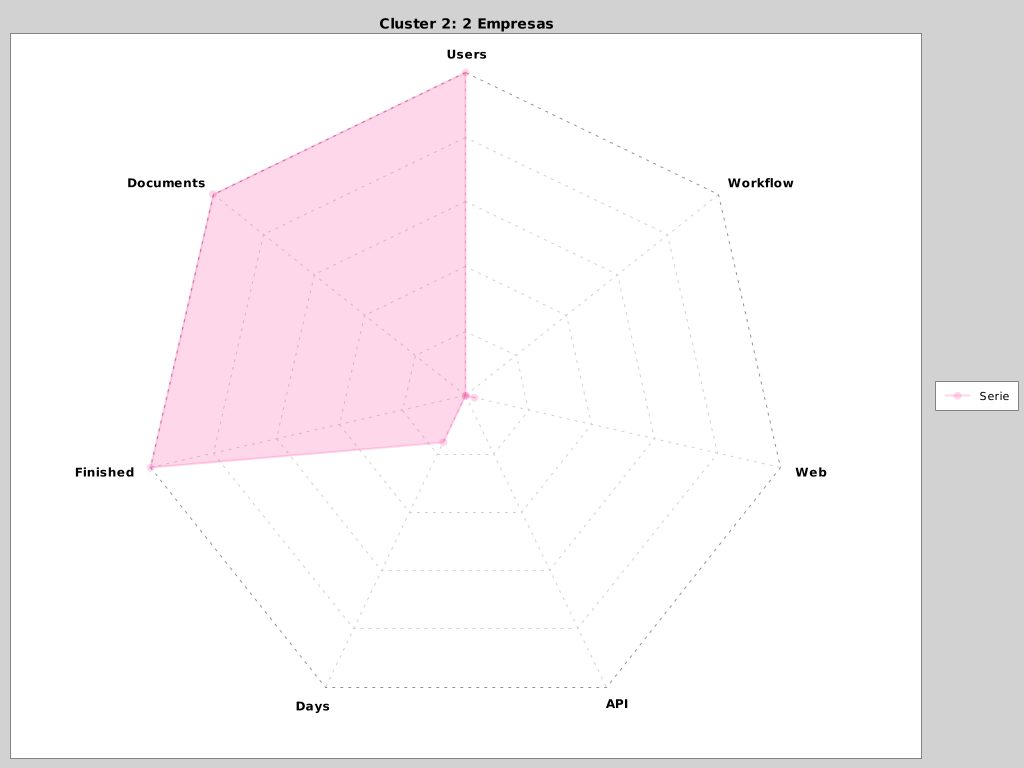
Figure 2. Ejemplo de cluster
O a ver que un par de empresas son capaces de terminar todo el flujo de creación de documentos pero empleando muchos usuarios por lo que podríamos ayudarles en mejorar las integraciones con API
En esta fase del proyecto tenemos 10 agrupaciones de clientes y cada una revela ciertas características y/o patrones que nos pueden ayudar a enfocar el diálogo de mejoras.
Así mismo trabajando "un poco" más en el script hemos parametrizado qué atributos nos interesan en cada ejecución de tal forma que en pocos segundos, de una forma sencilla, podemos obtener diferentes agrupaciones que nos descubren comportamientos de los clientes
Conclusion
En este post NO muestro todo el script, simplemente las partes de interés (además de que puede haber algún dato sensible) pero espero que sirva para exponer la idea principal de cómo agrupar clientes en función de múltiples atributos
Personalmente lo mejor para mí es poder seguir aplicando mis conocimientos de Apache Groovy y descubrir nuevos frameworks de Machine Learning sin tener que tocar una sóla línea de Python
- INFO
-
En este post encontrarás una explicación mejor de cómo hacer una agrupación de marcas de Wisky (que es en el que me he inspirado para este proyecto)