<PreciosEESSTerrestres xmlns="http://schemas.datacontract.org/2004/07/ServiciosCarburantes" xmlns:i="http://www.w3.org/2001/XMLSchema-instance">
<Fecha>06/08/2020 21:31:14</Fecha>
<ListaEESSPrecio>
<EESSPrecio>
<C.P.>02250</C.P.>
<Dirección>AVENIDA CASTILLA LA MANCHA, 26</Dirección>
<Horario>L-D: 07:00-22:00</Horario>
<Latitud>39,211417</Latitud>
<Localidad>ABENGIBRE</Localidad>
<Longitud_x0020__x0028_WGS84_x0029_>-1,539167</Longitud_x0020__x0028_WGS84_x0029_>
<Margen>D</Margen>
<Municipio>Abengibre</Municipio>
<Precio_x0020_Biodiesel/>
<Precio_x0020_Bioetanol/>
<Precio_x0020_Gas_x0020_Natural_x0020_Comprimido/>
<Precio_x0020_Gas_x0020_Natural_x0020_Licuado/>
<Precio_x0020_Gases_x0020_licuados_x0020_del_x0020_petróleo/>
<Precio_x0020_Gasoleo_x0020_A>1,039</Precio_x0020_Gasoleo_x0020_A>
<Precio_x0020_Gasoleo_x0020_B>0,569</Precio_x0020_Gasoleo_x0020_B>
<Precio_x0020_Gasoleo_x0020_Premium/>
<Precio_x0020_Gasolina_x0020_95_x0020_E10/>
<Precio_x0020_Gasolina_x0020_95_x0020_E5>1,149</Precio_x0020_Gasolina_x0020_95_x0020_E5>
<Precio_x0020_Gasolina_x0020_95_x0020_E5_x0020_Premium i:nil="true"/>
<Precio_x0020_Gasolina_x0020_98_x0020_E10/>
<Precio_x0020_Gasolina_x0020_98_x0020_E5/>
<Precio_x0020_Hidrogeno/>
<Provincia>ALBACETE</Provincia>
<Remisión>dm</Remisión>
<Rótulo>Nº 10.935</Rótulo>
<Tipo_x0020_Venta>P</Tipo_x0020_Venta>
<_x0025__x0020_BioEtanol>0,0</_x0025__x0020_BioEtanol>
<_x0025__x0020_Éster_x0020_metílico>0,0</_x0025__x0020_Éster_x0020_metílico>
<IDEESS>4375</IDEESS>
<IDMunicipio>52</IDMunicipio>
<IDProvincia>02</IDProvincia>
<IDCCAA>07</IDCCAA>
</EESSPrecio>
<!-- más estaciones-->
</ListaEESSPrecio>Static Site Estaciones de Servicio
- agosto, 22 2020
- Jorge Aguilera
- 11:00
El Ministerio de Industria y Consumo publica de forma diaria un dataset con los precios de todas las gasolineras de España. En este post voy a explicar cómo, de forma autónoma, se ejecuta un script que lo descarga y crea un site para poder navegar entre las más de 14.000 estaciones y consultar los precios del día.
El resultado final lo puedes ver aquí: https://estaciones-de-servicio.netlify.app/main/final/index.html
- NOTE
-
Tal vez te pueda interesar el post estaciones-servicio-bot.html donde detallo cómo hacer un bot de Telegram para consumir dichos datos.
Open Data
El site se basa en un conjunto de datos abiertos del Ministerio de Industria y Consumo donde se muestran los precios de las estaciones de servicio de España: https://sedeaplicaciones.minetur.gob.es/ServiciosRESTCarburantes/PreciosCarburantes/EstacionesTerrestres/
En este xml (o json) se listan todas las estaciones con su nombre, dirección, marca, geoposición así como los diferentes precios para gasolina 95, 98, los diferentes tipos de diesel, bios, etc.
Estos precios se actualizan al menos una vez al día (realmente no recuerdo donde leí cuando se realiza, ni la periodicidad)
A diferencia del bot en este caso lo que nos interesa es organizar todas las estaciones por provincias y municipios y para cada una de ellas mostrar la dirección, un enlace a su ubicación y los diferentes precios que tiene (no todas tienen todos los tipos de carburante).
El objetivo va a ser generar un site de "puro HTML" de tal forma que pueda ser publicado en alguno de los numerosos servicios que ofrecen de forma gratuita su publicación, en nuestro caso Gitlab/Netlify (Github es otra opción pero no lo uso)
Tools
Para tener listo el site vamos a utilizar las siguientes herramientas. De todas ellas la que puede varíar en tu caso es la que te ayude a generar los ficheros partiendo de los datos, en mi caso un script de groovy.
Groovy Script
Gracias a que con Groovy es muy fácil descargar e interpretar un XML (o un JSON) así como trabajar con ficheros de texto, lo usaremos para particionar y generar los ficheros
Antora/Asciidoctor
El script va a generar ficheros adoc (asciidoctor) que no es más que ficheros planos con un lenguaje de marcado que
será interpretado por Antora para generar la versión HTML correspondiente
Baśicamente serán ficheros muy sencillos con un título para el nombre de la provincia, subtitulo para los municipios, apartados para las gasolineras, enlaces, etc.
Esta es la pieza fundamental para que funcione el sistema y la que nos va a marcar qué estructura de ficheros tenemos que generar así como una serie de configuración
Gitlab
El proyecto va a estar alojado en mi cuenta gratuita de Gitlab como repositorio git. Una de las características de Gitlab es que te permite ejecutar código en sus sistemas incluso de una forma recurrente mediante jobs programados lo cual nos va a servir para tener actualizado el site todos los días.
Netlify
Gitlab nos permite publicar el contenido estático generado en el paso anterior pero para este post vamos a integrar el repositorio con otra herramienta con capa gratuita que permite de igual forma publicar contenido estático más alguna otra funcionalidad, que es Netlify (este paso te lo puedes saltar y utilizar Gitlab. La única diferencia es que Netlify a mi parecer tiene mejor velocidad de descarga)
Preparación
En primer lugar es importante entender la estructura de directorios que requiere Antora así como alguno de los ficheros necesarios.
Antora espera una estructura similar a la que se muestra en la imagen:
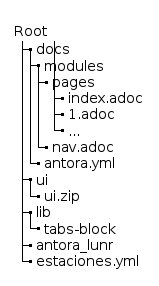
En primer lugar crearemos esta estructura de directorios y los ficheros excepto los que van en el directorio pages
que serán creados por el script. Por ello este directorio se encuentra excluido en el .gitignore pues no hace falta
versionarlos al cambiar cada vez que ejecutemos el script). Por la misma razón nav.adoc tampoco se versiona pues el
script se encargará de crear la navegación.
name: main title: Estaciones de Servicio version: final nav: - modules/ROOT/nav.adoc
Este fichero le indica a Antora qué modulos queremos cargar, en nuestro caso únicamente el ROOT
site:
title: Estaciones de Servicio
url: https://estaciones-de-servicio.netlify.com
start_page: main::index.adoc
keys:
google_analytics: 'UA-XXXXX-XX'
content:
sources:
- url: ./
branches: HEAD
start_path: docs
ui:
bundle:
url: ui/ui.zip
supplemental_files: antora-lunr/supplemental_ui
output:
clean: true
dir: ./build
destinations:
- provider: archive
asciidoc:
extensions:
- ./lib/tabs-block/extension.js
Este fichero es lo que en Antora se conoce como un playbook y sirve para indicarle de donde obtener los repositorios (Antora puede unir múltiples repositorios para generar un único site), la presentación a usar (ui.zip), extensiones, etc
En nuestro caso le estamos indicando que entre otras características utilice el directorio docs como origen para la
documentación junto con una serie de extras que nos van a ayudar a que nuestro site sea más funcional como una
extensión para mostrar multiples tabs, un buscador incluido (lunr)
Script
Para generar las páginas que va a usar Antora como fuente, el script simplemente va a :
-
descargarse el XML y parsearlo. Con groovy esto se puede hacer con una simple linea
new XmlParser().parseText(new InputStreamReader(url.toURL().openStream(), 'UTF-8').text).ListaEESSPrecio
-
recorrer cada estación, extraer la información de interés de cada una e ir añadiendolas a un "mapa de mapas" por provincia, municipios y localidades de tal forma que al terminar tenemos en memoria todas las estaciones agrupadas
[ Albacete : [Abengibre: [ [ Estacion1:[ precio95:1.23, precio98:1.33] ] ] ] ]
-
utilizando este mapa, el script genera el fichero de navegación:
nav = new File('docs/modules/ROOT/nav.adoc')
nav.text = ""
map.each{ kvp ->
provincia = kvp.value
nav << "* xref:${kvp.key}.adoc[$provincia.name]\n"
provincia.municipios.each{ kvm ->
municipio = kvm.value
nav << "** xref:${kvp.key}.adoc#${municipio.name.toLowerCase().replaceAll(' ','_')}[$municipio.name]\n"
}
}- NOTE
-
Añadir líneas a un fichero de texto en groovy es tan fácil como
file << "una cadena"
Básicamente indicamos que tendremos un fichero por cada provincia (01.adoc, 02.adoc, …) y que dentro de él tendremos secciones con el nombre de cada municipio. Para facilitar la navegación usaremos el nombre del municipio en minúsculas y cambiaremos los espacios en blanco por guiones bajos
Lo que nos genera un fichero parecido a:
nav.adoc
* xref:02.adoc[ALBACETE] ** xref:02.adoc#abengibre[Abengibre] ** xref:02.adoc#albacete[Albacete] ... ** xref:50.adoc#villarroya_de_la_sierra[Villarroya de la Sierra] ** xref:50.adoc#zaragoza[Zaragoza] ** xref:50.adoc#zuera[Zuera]
-
después el script vuelve a recorrer el mapa para ir generando los ficheros de cada provincia:
map.each{ kvp ->
provincia = kvp.value
file = new File("docs/modules/ROOT/pages/${kvp.key}.adoc") (1)
file.parentFile.mkdirs()
file.text ="= $provincia.name\n:tabs:\n\n" (2)
...
}| 1 | Creamos un fichero por provincia |
| 2 | Lo inicializamos con una cabecera asciidoctor con su titulo y el atributo :tabs: |
Para cada provincia recorremos sus municipios y localidades
map.each{ kvp ->
...
provincia.municipios.each{ kvm ->
municipio = kvm.value
file << "[#${municipio.name.toLowerCase().replaceAll(' ','_')}]\n"
file << "== $municipio.name \n\n"
municipio.localidades.each{ kvl ->
kvl.value.sort{it.direccion}.each{ estacion ->
file << "=== $estacion.direccion \n\n"
file << "*$estacion.rotulo* $estacion.horario \n\n"
file << "https://www.openstreetmap.org/?mlat=$estacion.latitud&mlon=$estacion.longitud#map=17/$estacion.latitud/$estacion.longitud[Ver en mapa,window=_blank]\n\n"
file << "[TIP]\n====\n"
estacion.precios.findAll{ it.value }.each{
file << "* _${it.key}_ a *${it.value}* €\n"
}
file << "====\n\n"
}
}
}
...
}Como se puede adivinar, simplemente vamos concatenando al fichero de la provincia texto en formato asciidoc hasta que llegamos a una estación donde volcamos sus datos.
Para cada provincia se genera un fichero similar a:
= ARABA/ÁLAVA
:tabs:
[#alegría-dulantzi]
== Alegría-Dulantzi
=== CALLE GASTEIZBIDEA 59
*ES DULANTZI REPSOL* L-D: 07:00-22:00
https://www.openstreetmap.org/?mlat=42.842917&mlon=-2.519194#map=17/42.842917/-2.519194[Ver en mapa,window=_blank]
[TIP]
====
* _95 E5_ a *1.239* €
* _Gasoleo A_ a *1.139* €
====
(más estaciones)- WARNING
-
El script actual genera algo más de código por cada provincia como una serie de tabs con las estaciones más baratas al inicio del fichero. En este post no voy a explicarlo pero si te interesa es muy fácil de seguir.
-
por último el script copia un fichero
index.adocque se encuentra en el raiz del proyecto al raiz del pages del módulo. De esta forma puedo cambiar la página principal sin liar más el script.
-
Para generar las páginas simplemente ejecuto:
groovy dump.groovy
- NOTE
-
Este script será ejecutado por el pipeline de Gitlab por lo que al final no necesitarías ni tener Groovy instalado en tu local, aunque sería bueno tenerlo para probarlo primero antes de pasar a publicarlo.
Generar el site
Una vez ejecutado el script y las páginas generadas podemos proceder a ejecutar Antora para que nos genere el site. Puedes instalarlo y ejecutarlo desde una consola o utilizar un docker-compose como el siguiente para evitarlo:
docker-compose.yml
version: "2.1"
services:
antora:
image: "antora/antora"
volumes:
- .:/antoray ejecutarlo mediante
docker-compose run antora estaciones.yml
Este docker usaría la imagen oficial de antora, básica pero suficiente para generar un site en el directorio build
que podrías revisar con un navegador.
Sin embargo esta imagen no incluye ciertas extensiones que me interesan como el buscador javascript por lo que habría que instalarlo y configurarlo, así que yo me he creado mi propia imagen donde ya se encuentra instalado y este es el docker-compose que utilizo:
version: "2.1"
services:
antora:
image: "jagedn/antora-with-extensions"
environment:
- DOCSEARCH_ENABLED=true
- DOCSEARCH_ENGINE=lunr
- NODE_PATH="$$(yarn global dir)/node_modules"
volumes:
- .:/antoraEjecución diaria
Como he comentado, una de las características de Gitlab es que puedes programar la ejecución de pipelines, no sólo cuando realizas cambios en el código y los subes al repositorio sino de forma programada.
Nuestro pipeline consistirá en 3 pasos consecutivos:
gitlab-ci.yml
stages:
- build
- staging
- deploy
groovy:
stage: build
image:
name: groovy:2.5.9
script:
- groovy dump.groovy
artifacts:
paths:
- docs
antora:
stage: staging
image:
name: jagedn/antora-with-extensions
entrypoint: [/bin/sh, -c]
variables:
ASCIIDOC_COPY_TO_CLIPBOARD: "true"
DOCSEARCH_ENABLED: "true"
DOCSEARCH_ENGINE: "lunr"
NODE_PATH: "$$(yarn global dir)/node_modules"
dependencies:
- groovy
script:
- antora --generator antora-site-generator-lunr estaciones.yml
artifacts:
paths:
- build
pages:
stage: deploy
dependencies:
- antora
script:
- mkdir -p public
- cp -R build/* public/
artifacts:
paths:
- publicSi todo va bien, Gitlab nos ofrecerá una url donde publicará el site generado por antora. En este caso en https://jorge-aguilera.gitlab.io/estaciones-de-servicio
Netlify
Netlify es otro servicio de hosting con características muy interesantes que integra fácilmente con Gitlab (y otros) de tal forma que podemos delegar en este segundo la ejecución de nuestro pipeline mientras que utilizamos a Netlify como plataforma donde desplegarlo.
Para ello simplemente:
-
crearemos un proyecto en Netlify
-
obtendremos su NETLIFY_SITE_ID
-
desde la página del perfil crearemos un NETLIFY_AUTH_TOKEN
-
crearemos en Gitlab dos variables de entorno nuevas en la seccion CD/CI con estos valores
-
sustituiremos el último paso del fichero .gitlab-ci.yml por este otro (o si quieres publicar en los dos sitios lo puedes mantener, simplemente estarás publicando en los dos URLs a la vez)
netlify:
stage: deploy
image: node:10.15.3
script:
- npm i -g netlify-cli
- netlify deploy --site $NETLIFY_SITE_ID --auth $NETLIFY_AUTH_TOKEN --prod
dependencies:
- antora
only:
- master